[Digital Forensic] 볼륨과 파티션

파일 시스템이 위치하는 볼륨과 파티션 구조를 모르고서는 파일 시스템을 정확히 분석해낼 수 없다.
대부분 파티션과 볼륨을 혼용하여 사용하는데 정확히 구분하면 이는 잘못된 사용이다.
(1) 볼륨
-
운영체제나 응용 프로그램이 데이터를 저장해 사용하도록 주소가 지정된 섹터들의 집합
-
섹터들이 연속적이지 않다라는 뜻을 가짐
볼륨은 다음과 같이 두 가지 개념을 가진다.
-
여러 개의 저장 볼륨에서 한 개의 저장 볼륨으로 조합하는 것 (더 작은 볼륨들로 나뉘거나 더 큰 볼륨으로 합쳐질 수 있음)
-
저장 볼륨들을 독립적인 파티션들로 분할하는 것
Windows와 Unix의 볼륨 사용 차이
-
Windows 경우 C, D와 같은 드라이브 문자가 있으나, Unix의 경우 이러한 문자들이 없음
-
Unix는 / 로 시작하는 루트 디렉토리가 존재하며, 하위에 다른 디렉토리나 볼륨 위치
볼륨 분석은 조사관이 수행한다기 보다는 도구에 의해 일반적으로 진행된다.
분석 기술은 의외로 간단하며, 분석 도구들의 분석 방법을 살펴보면 대부분 파티션 테이블의 위치를 확인하고 그 값을 읽어 그 정보를 출력하여 준다.
테이블에는 파티션 시작, 마지막 섹터 값, 파티션 유형 등의 정보가 들어 있으며 이 정보를 토대로 파티션 시스템(이미지)에서 각 볼륨들을 파악한다.
그리고 일관성 검사라는 것이 있는데 이 검사는 파티션을 제외한 영역에 증거가 존재하는지 조사하는 기능이다.
조사관은 파티션 테이블을 확인하여 파티션의 시작과 마지막 섹터를 확인하고 각 파티션들을 목록화하여 파티션 사이에 할당되지 않은 섹터가 있는지 확인하여 그곳에 증거가 없는지 분석하여야 한다.

위 그림은 DOS 파티션 내부 파일 시스템 파티션을 보기 쉽게 그림으로 표현한 것이다.
이러한 정보들로 파티션 내부의 파일 시스템 파티션을 추출할 수 있으며 도구로는 dd를 사용할 수 있다.
dd의 사용 방법은 다음과 같다.
dd if=<DOS 파티션 이미지> of=<추출 결과 저장 파일명> bs=<한번에 읽어 들일 블록 크기> skip=<건너 뛸 길이> count=<길이>
위와 같이 파티션 내부 파일 시스템 파티션을 추출해도 되지만 요즘 도구들은 파티션과 파일 시스템 분석을 모두 하여 데이터까지 조사관에게 보여줘 특별한 경우가 아니라면 위와 같이 일일이 파일 시스템을 이미지에서 분리해내지 않아도 된다.
대표적으로는 AccessData의 FTK와 Guidance의 EnCase가 있다.
(2) 파티션
-
볼륨 색터들의 연속적인 것
-
일반적으로 파티션은 파티션 테이블이라는 것을 가짐
-
흔히 파티션을 구성할 때, 볼륨의 레이아웃을 구성하는 것을 말하는 데 레이아웃을 구성하기 위해서는 파티션 테이블 값이 절대적으로 필요
-
파티션 테이블이 잘못된 값을 갖는다면 볼륨 레이아웃은 정상적으로 작동하지 않음
-
파티션 테이블에도 부가적인 필드들이 존재하며, 필드들의 값은 볼륨 레이아웃 구성과 관련이 없어 값이 잘못되도 상관 없음
2-1. 도스 파티션
-
우리가 흔히 사용하는 컴퓨터 파티션 형식
-
자주 사용하고 흔히 접하는 도스 파티션은 정확한 명세가 제공되지 않음
-
Microsoft는 이런 파티션 시스템을 MBR(Master Boot Record) 디스크라고 부름
-
도스 파티션은 도스, 윈도우, 리눅스 IA32 기반 FreeBSD와 OpenBSD 시스템에서 사용
-
흔한 시스템이지만 의외로 복잡한 구성을 가짐ㅁ
-
도스 파티션을 사용하는 Disk는 512Byte 섹터 내의 MBR을 갖고 있음
MBR에는 다음과 같은 정보가 있다.
1) 부트코드
2) 파티션 테이블
-
파티션 시작 CHS 주소
-
파티션 마지막 CHS 주소
-
파티션 시작 LBA 주소
-
파티션 섹터 수
-
파티션 타입
-
플래그
3) 시그니처
CHS(Cylinder, Head, Sector)는 8GB 이하 디스크에서만 사용이 가능하며, LBA는 TB(TeraByte) 크기의 디스크까지 사용 가능하다.
파티션 타입은 파일 시스템을 나타내는 것으로, Ext, NTFS, HFS+ 등이 있다.
운영체제들은 운영체제별로 파티션 타입이 다르며 리눅스는 파티션을 마운트할 때에 파티션 타입을 참조하지 않아 NTFS 파티션 타입이어도 리눅스 파티션 타입인 FAT으로 파티션을 마운트한다.
이와 달리 윈도우 경우 파티션 타입을 참조하여 NTFS 타입이 아니면 마운트하지 못한다.
위와 같은 방법으로 파티션을 숨길 수 있는 방법이 있다.
간단히 설명하자면, 파티션 타입에 1비트를 변조하여 윈도우에서 파티션을 인식하지 못하게 하는 것이다.
플래그는 파티션 부팅 여부를 나타내는 항목이며, 컴퓨터가 부팅할 때 운영체제가 어떤 파티션에 위치하고 있는지 구분할 때 사용된다.
MBR은 4개의 파티션만 표현할 수 있으며 4개의 엔트리를 이용하여 파티션들이 할당된 디스크 구조를 표현할 수 있다.
하지만 사용자에 따라 4개 이상의 파티션이 필요할 때가 있으며, 이러한 경우를 위해 확장 파티션 개념이 생겼다.

확장 파티션 개념은 3개의 파티션은 기본적인 파티션으로 두고 나머지 1개의 파티션을 확장 파티션으로 만들고 그 안에 또 다른 파티션들을 만드는 것이다.
예를 들어 12GB의 디스크에 6개 파티션을 구성하려고 하면 확장 파티션 개념으로 해야 할 것이다.

부 파티션 앞에 있는 MBR들은 위 [그림 3]과 같은 방법으로 모두 부 파티션과 부 확장 파티션을 갖게 된다.
부 파티션 1, 2를 만들고 부 확장 파티션 1을 만들게 되며 대부분의 OS에서는 세 번째 파티션을 무시하게 되어 '부 확장 파티션1'이 인식이 되지 않는다. (크기를 잘못 인식하는 경우도 발생)
확장 파티션에는 파티션 테이블 엔트리에서 사용되는 특별한 타입들이 있는데 위와 같이 복잡한 구조가 된 것은 확장 파티션 타입이 여러 가지 종류가 있으며 파티션 사이를 구분하기 어렵기 때문이다.
부트 코드
-
MBR 섹터 내에 1~446 바이트에 존재하며, 나머지는 파티션 테이블 엔트리
-
MBR 파티션 테이블을 처리한 후 부팅 플래그가 있는 파티션을 찾고 부팅 가능한 파티션의 첫 번째 섹터를 찾은 후 운영체제 코드를 실행시킴
-
이 영역에 바이러스 침투 시, OS 부팅 시 바이러스도 함께 OS 부팅 시 매번 실행되는 것
-
부트코드를 수정하면 OS 멀티 부팅이 가능
MBR
-
512 Byte 크기의 구조체를 사용
-
첫 446Byte는 어셈블리 부트 코드를 위해 예약이 되어 있음
MBR은 다음 표와 같은 내용들을 담고 있다.
|
범위(Byte) |
설명 |
범위(Byte) |
설명 |
|
0 ~ 445 |
부트 코드 |
478 ~ 493 |
파티션 테이블 엔트리 3 |
|
446 ~ 461 |
파티션 테이블 엔트리 1 |
494 ~ 509 |
파티션 테이블 엔트리 4 |
|
462 ~ 477 |
파티션 테이블 엔트리 2 |
510 ~ 511 |
시그니처 (0xAA55) |
MBR은 기본적으로 4개의 파티션을 파티션 테이블 엔트리(16Byte)로 표현할 수 있어 파티션 테이블 엔트리가 4개이다.
각 파티션 레이아웃을 구성하는 파티션 테이블 엔트리의 구조는 다음과 같다.
|
범위(Byte) |
설명 |
범위(Byte) |
설명 |
|
0 ~ 0 |
부팅 플래그 |
5 ~ 7 |
파티션 끝 CHS 주소 |
|
1 ~ 3 |
파티션 시작 CHS 주소 |
8 ~ 11 |
파티션 시작 LBA 주소 |
|
4 ~ 4 |
파티션 타입 |
12 ~ 15 |
섹터 크기 |
부팅 플래그는 반드시 필요한 것은 아니다.
하나의 운영체제가 설치되어 있는 시스템(부팅 플래그 default : 0x80)이라면 부팅 플래그가 필요해지며, 여러 운영체제를 멀티 부팅하는 시스템이라면 사용자가 OS 부팅을 선택하기 때문에 이러한 경우에는 부팅 플래그가 필요 없다.
위 표에서 CHS 항목 두 가지가 있는데 이 항목들은 최신 시스템에서는 필수적이지 않다.
파티션 타입은 파일 시스템 타입을 구분짓기 위해 필요한 항목이다.
주요 파티션 타입 목록은 다음 표와 같다.
|
타입 |
설명 |
타입 |
설명 |
|
0x00 |
Empty |
0x83 |
Linux |
|
0x01 |
FAT12, CHS |
0x84 |
Hibernation Mode |
|
0x04 |
FAT16, 16 ~ 32MB, CHS |
0x85 |
Linux Extended |
|
0x05 |
Microsoft Extended, CHS |
0x86 |
NTFS Volume Set |
|
0x06 |
FAT 32MB ~ 2GB, CHS |
0x87 |
NTFS Volume Set |
|
0x07 |
NTFS |
0xA0 |
Hibernation Mode |
|
0x0B |
FAT32, CHS |
0xA1 |
Hibernation Mode |
|
0x0C |
FAT32, LBA |
0xA5 |
FreeBSD |
|
0x0E |
FAT16, 32MB ~ 2GB, LBA |
0xA6 |
OpenBSD |
|
0x0F |
Microsoft Extended, LBA |
0xA8 |
Mac OS X |
|
0x11 |
Hidden FAT12, CHS |
0xA9 |
NetBSD |
|
0x14 |
Hidden FAT16, 16 ~ 32MB, CHS |
0xAB |
Mac OS X Boot |
|
0x16 |
Hidden FAT16, 32MB ~ 2GB, CHS |
0xB7 |
BSDI |
|
0x1B |
Hidden FAT32, CHS |
0xB8 |
BSDI Swap |
|
0x1C |
Hidden FAT16, 16 ~ 32MB, LBA |
0xEE |
EFI GPT Disk |
|
0x42 |
Microsoft MBR, Dynamic Disk |
0xEF |
EFI System Partition |
|
0x82 |
Solaris x86 |
0xFB |
VMware File System |
|
0x82 |
Linux Swap |
0xFC |
VMware Swap |
확장 파티션 MBR 또한 위 MBR의 구조와 다를 바가 없으나 시작 섹터의 주소가 디스크 특정 지점의 상대적 주소이기 때문에 파티션 테이블 엔트리가 조금 다르다.
-
부 파일 시스템 엔트리 시작 주소는 현태 파티션 테이블 주소에서 상대적 주소
-
부 확장 파티션 엔트리 시작 주소는 주 확장 파티션에서 상대적
요즘은 디스크 레이아웃을 분석해 주는 도구들이 많이 개발되어 있어 조사관들이 사건 조사하기 편하게 해주기는 하지만 도스 파티션 경우 흔하게 접할 수 있는 파티션 시스템이므로 도스 파티션애 대해서는 필히 알고 있어야 한다.
2-2. 애플 파티션
-
도스 파티션보다 적게 사용되지만 사용자가 증가하고 있는 추세이며 여러 장비들에 애플 파티션이 적용
-
매킨토시 시스템에는 파티션 맵이라고 하는 이미지가 있는데 이것은 매킨토시 시스템이 파일들을 전송하기 위해 사용하는 디스크 이미지
-
파티션 맵 이미지 디스크는 윈도우 zip 파일, 유닉스 tar 파일과 유사한 형태
-
파티션 맵은 데이터 영역 위치, 부트 코드 위치 등의 데이터를 가짐

[그림 4]에서 보는 것처럼 파티션 맵은 첫 번째 엔트리가 자신의 엔트리이고 나머지 엔트리가 파티션 엔트리이다.
파티션 맵에서 파티션 맵 엔트리는 파티션 맵의 최대 크기를 나타낸다.
파티션 맵은 MBR과 동일하게 512Byte 크기이며, 여러 구조체로 구성되고 두 번째 섹터에서 시작한다.
또 모든 파티션을 배치할 때까지 구조체를 계속 할당한다.
파티션 데이터 구조체들은 연속적인 섹터들 내에 구성되며, 각 맵 엔트리는 전체 파티션 수를 나타낸다.
다음은 애플 파티션 맵 엔트리 오프셋 구조이다.
|
범위(Byte) |
설명 |
범위(Byte) |
설명 |
|
0 ~ 1 |
시그니처 (0x504D) |
92 ~ 95 |
부트 코드 시작 섹터 |
|
2 ~ 3 |
예약 영역 |
96 ~ 99 |
부트 코드 크기 |
|
4 ~ 7 |
파티션 총 개수 |
100 ~ 103 |
부트 적재 코드 주소 |
|
8 ~ 11 |
파티션 시작 섹터 |
104 ~ 107 |
예약 영역 |
|
12 ~ 15 |
파티션 크기 |
108 ~ 111 |
부트 코드 엔트리 지점 |
|
16 ~ 47 |
파티션 이름 |
112 ~ 115 |
예약 영역 |
|
48 ~ 49 |
파티션 타입 (ASCII) |
116 ~ 119 |
부트 코드 체크섬 |
|
80 ~ 83 |
데이터 영역의 파티션 시작 |
102 ~ 135 |
프로세서 타입 |
|
84 ~ 87 |
데이터 영역 크기 |
136 ~ 511 |
예약 영역 |
|
88 ~ 91 |
파티션 상태 |
위 표의 데이터 구조체 항목들 중 파티션 상태 영역이 있는데 이 필드는 다음 표의 목록들 중 하나의 값을 가진다.
|
타입 |
설명 |
|
0x00000001 |
앤트리 유효 (A/UX만 해당) |
|
0x00000002 |
엔트리 할당 (A/UX만 해당) |
|
0x00000004 |
엔트리 사용 중 (A/UX만 해당) |
|
0x00000008 |
엔트리가 부트 정보를 포함 (A/UX만 해당) |
|
0x00000010 |
파티션 읽기 가능 (A/UX만 해당) |
|
0x00000020 |
파티션 쓰기 가능 (매킨토시, A/UX만 해당) |
|
0x00000040 |
부트 코드 위치가 독립적 (A/UX만 해당) |
|
0x00000100 |
파티션이 연결-호환 드라이버를 포함 (매킨토시만 해당) |
|
0x00000200 |
파티션이 실제 드라이버를 포함 (매킨토시만 해당) |
|
0x00000400 |
파티션이 연결 드라이버를 포함 (매킨토시만 해당) |
|
0x40000000 |
시작될 때 자동으로 마운트 (매킨토시만 해당) |
|
0x80000000 |
시작 파티션 (매킨토시만 해당) |
조사할 때 파티션 맵은 두 번째 섹터에서 시작하므로 애플 디스크의 파티션들을 구분하려면 두 번째 섹터에서 파티션 맵의 데이터 구조체들을 통해 정보를 수집해야 한다.
애플 디스크의 파티션들을 분석할 경우 고려해야 할 사항으로는 파티션 맵의 구조체 데이터들 중 사용되지 않는 필드들이 있어 적은 양의 데이터가 사용되지 않는 필드에 숨겨질 수 있다.
또 파티션 데이터 구조체와 파티션 맵 끝 사이 섹터에 데이터가 숨겨질 수도 있다.
2-3. BSD 파티션
-
컴퓨터 포렌식 조사 대상에는 BSD 시스템들이 많이 속함 (리눅스도 마찬가지)
-
IA32 기반 하드웨어(x86/i386)를 사용하며 자체 분할 시스템을 사용
-
IA32 기반 하드웨어를 사용하기 때문에 MS 제품들과 같은 디스크에 공존할 수 있도록 설계됨
-
도스 파티션보다 간단하기 때문에 이해하는 데 매우 쉬움
-
단점으로 애플 파티션 맵보다는 약간의 한계점을 가짐
-
도스 파티션과 공존할 수 있기 때문에 도스 파티션에서 생성한 볼륨에 위치할 수 있음
-
즉 '주 도스 파티션'이 될 수 있음
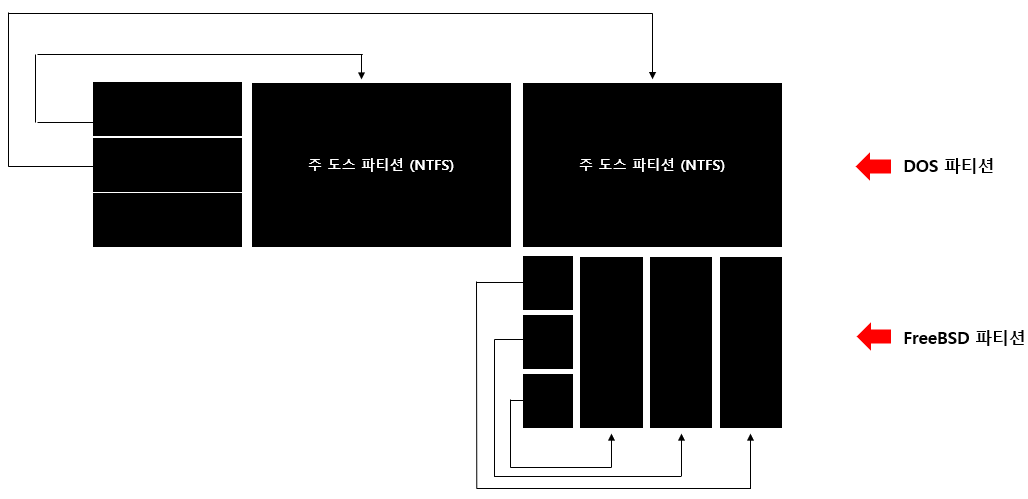
BSD 파티션의 핵심은 디스크 레이블(Disk Label)이다.
최소 크기는 276Byte이며 BSD 파티션 두 번째 섹터에 위치한다.
일부 IA32가 아닌 시스템들은 첫 번째 섹터에 위치하기도 한다.
디스크 레이블의 구조체들은 디스크 하드웨어 명세서를 포함하고, 8개 또는 16개의 BSD 파티션 테이블을 포함한다.
애플 파티션 맵과 다르게 BSD 파티션 테이블은 크기가 고정적이다.
BSD 파티션 테이블의 엔트리 항목들은 다음과 같다.
-
BSD 파티션 시작 섹터 주소 : 도스 파티션이나 디스크 레이블에서의 상대적 주소가 아닌 디스크 시작 주소에서의 상대적 주소
-
BSD 파티션 크기
-
파티션 타입 : BSD 파티션에 있는 파일 시스템 타입을 구분할 때 쓰이는 항목
-
UFS 파일 시스템 조각 크기
-
블록당 UFS 파일 시스템 조각의 수
-
UFS 실린더 그룹 당 실린더 개수
마지막 3개 항목은 UFS 파일 시스템을 포함할 때만 사용된다.
BSD 파티션은 구조체 하나를 읽어서 전체 파티션 구조를 파악한다.
2-4. FreeBSD
-
하나의 디스크에서 도스 파티션과 BSD 파티션 둘 다 사용할 수 있도록 되어 있음
-
FreeBSD에서 도스 파티션은 '슬라이스'라는 용어로 불리며, BSD 파티션은 '파티션'으로 불림
-
디스크 레이블 구조체는 FreeBSD 도스 파티션에 있으며, 그 구조체는 도스 파티션 내 존재하는 BSD 파티션 레이아웃을 구성하는데 쓰임
-
FreeBSD는 각 파티션과 슬라이스에 특별한 장치 이름을 부여하는데 슬라이스의 경우 디스크 기본 이름에 's'와 번호를 부여
-
파티션의 경우 슬라이스 이름에 알파벳으로 순서를 매김
파티션의 경우 이름을 줄일 수도 있는데 다음 그림과 같다.

BSD 파티션은 이름에 따라 특별한 의미를 갖게 되는데 'a' 라는 이름을 할당 받은 파티션의 경우 보통 부트 코드가 위치하고 있는 파티션이 된다.
'b' 이름을 할당 받은 파티션은 보통 스왑 공간을 나타내며, 'c' 이름을 할당 받은 파티션은 보통 전체 슬라이스를 나타내고, 'd' 이름을 할당 받은 파티션은 보통 어떠한 파티션도 될 수 있는 파티션을 나타낸다.
하지만 이 이름 부여 원칙은 절대적이 아니며 수정이 가능하다.
2-5. OpenBSD (NetBSD)
-
원래 OpenBSD 코드와 NetBSD 코드는 함께 있었지만 지금은 따로 분리 됨 (같은 구조라고 보면 됨)
-
OpenBSD에서는 도스 파티션이 단지 OpenBSD 파티션의 시작 부분을 확인시켜 주기 위해서만 사용되기 때문에 OpenBSD 커널이 적재되어 실행되면 도스 파티션은 무시
-
이름 할당 방법은 FreeBSD와 동일하지만, 슬라이스 개념은 없음
-
BSD 시스템 부트 코드는 첫 번째 섹터에 위치 (항상 이런 것은 아님)
BSD 파티션에서 디스크 구조 정보를 가지고 있는 디스크 레이블의 구조는 다음 표와 같다.
|
범위(Byte) |
설명 |
범위Byte) |
설명 |
|
0 ~ 3 |
시그니처(0x82564557) |
112 ~ 131 |
예약 영역 |
|
4 ~ 5 |
드라이브 타입 |
132 ~ 137 |
체크섬 |
|
6 ~ 7 |
드라이브 하위 타입 |
138 ~ 139 |
파티션 번호 |
|
8 ~ 23 |
드라이브 타입 이름 |
140 ~ 143 |
부트 영역 크기 |
|
24 ~ 39 |
팩 식별자 이름 |
144 ~ 147 |
파일 시스템 부트 슈퍼 블록 최대 크기 |
|
40 ~ 43 |
섹터 크기(Byte) |
148 ~ 163 |
BSD 파티션 1 |
|
44 ~ 47 |
트랙 섹터 개수 |
164 ~ 179 |
BSD 파티션 2 |
|
48 ~ 51 |
실린더 트랙 개수 |
180 ~ 195 |
BSD 파티션 3 |
|
52 ~ 55 |
유닛 실린더 개수 |
196 ~ 211 |
BSD 파티션 4 |
|
56 ~ 59 |
실린더 섹터 개수 |
212 ~ 227 |
BSD 파티션 5 |
|
60 ~ 63 |
유닛 섹터 개수 |
228 ~ 243 |
BSD 파티션 6 |
|
64 ~ 65 |
트랙 Sparse 섹터 개수 |
244 ~ 259 |
BSD 파티션 7 |
|
66 ~ 67 |
실린더 Sparse 섹터 개수 |
260 ~ 275 |
BSD 파티션 8 |
|
68 ~ 71 |
유닛 보조 실린거 개수 |
276 ~ 291 |
BSD 파티션 9 |
|
72 ~ 73 |
디스크 회전 속도 |
292 ~ 307 |
BSD 파티션 10 |
|
74 ~ 75 |
하드웨어 섹터 교대 배치 |
308 ~ 323 |
BSD 파티션 11 |
|
76 ~ 77 |
트랙 스큐 |
324 ~ 339 |
BSD 파티션 12 |
|
78 ~ 79 |
실린더 스큐 |
340 ~ 355 |
BSD 파티션 13 |
|
80 ~ 83 |
헤드 전환 시간(ms) |
356 ~ 371 |
BSD 파티션 14 |
|
84 ~ 87 |
트랙에서 트랙 검색 시간(ms) |
372 ~ 387 |
BSD 파티션 15 |
|
88 ~ 91 |
플래그 |
388 ~ 403 |
BSD 파티션 16 |
|
92 ~ 111 |
드라이브 관련 정보 |
404 ~ 511 |
사용 X |
BSD 파티션 레이아웃 오프셋 구조는 다음과 같다.
|
범위(Byte) |
설명 |
범위(Byte) |
설명 |
|
0 ~ 3 |
BSD 파티션 섹터 크기 |
12 ~ 12 |
파일 시스템 타입 |
|
4 ~ 7 |
BSD 파티션 시작 섹터 |
13 ~ 13 |
블록별 파일 시스템 조각 개수 |
|
8 ~ 11 |
파일 시스템 조각 크기 |
14 ~ 15 |
그룹별 파일 시스템 실린더 개수 |
파일 시스템 타입은 BSD 파티션이 위치한 파일 시스템의 타입값을 가지며 목록은 다음과 같다.
|
타입값 |
설명 |
타입값 |
설명 |
|
0 |
비사용 슬록 |
8 |
MS-DOS File System(FAT) |
|
1 |
Swap 공간 |
9 |
4.4 BSD Log-Structured File System(4.4 LFS) |
|
2 |
Version 6 |
10 |
사용 중이지만 알려지지 않았으며, 지원되지 않음 |
|
3 |
Version 7 |
11 |
OS/2 HPFS |
|
4 |
System V |
12 |
CD-ROM(ISO9660) |
|
5 |
4.1 BSD |
13 |
Bootstrap |
|
6 |
8번째 출시 |
14 |
Vinum 드라이브 |
|
7 |
4.2 BSD Fast File Systems(FFS) |
FreeBSD와 OpenBSD 파일 시스템은 4.2BSD FFS(타입값:7)이며, 적어도 해당 시스템에서 Swap 파티션은 하나 이상 있어야 한다.
2-6. 솔라리스 파티션
-
솔라리스 운영체제는 대용량 서버와 데스크탑용으로 나누어져 있지만 대부분 대용량 서버에서 많이 사용하는 운영체제
-
그렇기 때문에 침해사고 조사 시 솔라리스 운영체제를 많이 볼 수 있어 파티션에 대한 이해 필요
-
솔라리스 모든 버전들은 BSD 디스크 레이블과 비슷한 구조 사용
-
Sparc 솔라리스와 i386 솔라리스로 나뉘며, 두 종류의 파티션 데이터 구조 역시 다름
솔라리스에서는 각 파티션을 지칭하는 용어로 '슬라이스'를 사용한다.
솔라리스 설치 시에 디스크에 디스크 레이블을 솔라리스가 생성하게 되며, 정확히 설치되는 위치는 하드웨어 플랫폼에 따라 다르며, 생성되는 디스크 레이블에는 파티션 최대 개수 정보가 들어 있다.
디스크 레이블은 Sparc 시스템의 경우 최대 개수 8개, i386 시스템의 경우 16개이며, 각 파티션은 다음과 같은 항목들을 가진다.
-
파티션 시작 위치
-
파티션 크기
-
플래그 세트
-
플래그 세트 크기
-
파티션 타입
플래그의 경우 파티션이 읽기 전용인지 스왑(Swap) 공간처럼 마운트가 불가능한지 판단하게 해 주는 항목이다.
파티션 타입 항목은 다른 시스템 파티션과 다르게 파티션 파일 시스템 타입을 설명하는 항목이 아닌 파티션 마운트 지점을 설명하는 항목이다.
솔라리스 파티션의 경우 이름 할당 방법이 다른 시스템 파티션들과는 조금 다르다.
다음과 같은 규칙을 적용하여 이름을 할당한다.

Sparc 시스템
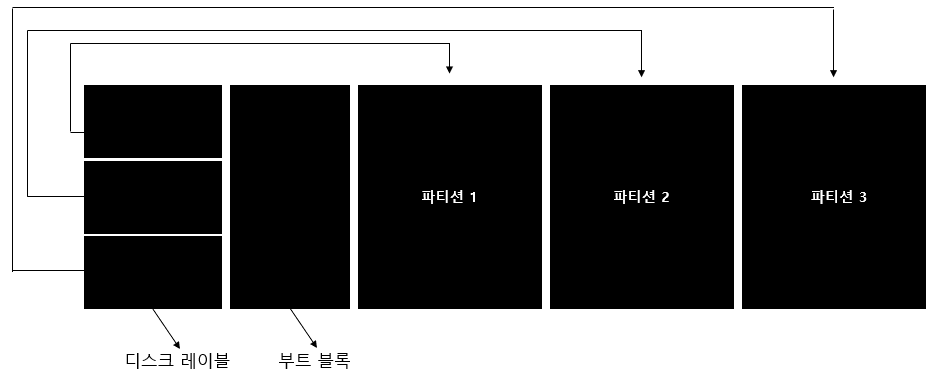
-
Sparc 시스템 디스크 레이블 구조체는 디스크 1번째 섹터에 생성
-
2번째 섹터부터 16번째 섹터까지는 부트 코드가 위치하는 부트 블록
-
부트 블록 바로 다음 섹터부터는 파일 시스템 등을 저장하는 파티션 영역
다음은 기본적인 Sparc 시스템의 디스크 레이아웃이다.
Sparc 디스크 레이블은 파티션 모든 정보를 직접적으로 담고 있지는 않으며 두 개의 구조체에 파티션 정보를 나누어 저장한다.
sparc VTOC(Volume Table Of Contents)라는 구조체와 파티션 디스크 맵이라는 구조체로 나뉘어 저장된다.
먼저 디스크 테이블의 항목들로부터 살펴 보면 다음 표와 같다.
|
범위(Byte) |
설명 |
범위(Byte) |
설명 |
|
0 ~ 127 |
ASCII 테이블 |
438 ~ 439 |
트랙 섹터 개수 |
|
128 ~ 261 |
Sparc VTOC |
440 ~ 443 |
예약 영역 |
|
262 ~ 263 |
Sectors to skip, Writing |
444 ~ 451 |
파티션 1 디스크 맵 |
|
264 ~ 265 |
Sectors to skip, Writing |
452 ~ 459 |
파티션 2 디스크 맵 |
|
266 ~ 419 |
예약 영역 |
460 ~ 467 |
파티션 3 디스크 맵 |
|
420 ~ 421 |
디스크 스피드 |
468 ~ 475 |
파티션 4 디스크 맵 |
|
422 ~ 423 |
물리적 실린더 개수 |
476 ~ 483 |
파티션 5 디스크 맵 |
|
424 ~ 425 |
실린더별 대체 개수 |
484 ~ 491 |
파티션 6 디스크 맵 |
|
426 ~ 429 |
예약 영역 |
492 ~ 499 |
파티션 7 디스크 맵 |
|
430 ~ 431 |
인터리브 |
500 ~ 507 |
파티션 8 디스크 맵 |
|
432 ~ 433 |
데이터 실린더 개수 |
508 ~ 509 |
시그니처 (0xDABE) |
|
434 ~ 437 |
헤드 개수 |
510 ~ 511 |
체크섬 |
파티션 정보를 저장하는 VTOC 구조체는 다음 표와 같다.
|
범위(Byte) |
설명 |
범위(Byte) |
설명 |
|
0 ~ 3 |
버전(0x01) |
40 ~ 41 |
파티션 7 플래그 |
|
4 ~ 11 |
볼륨 이름 |
42 ~ 43 |
파티션 8 타입 |
|
12 ~ 13 |
파티션 개수 |
44 ~ 45 |
파티션 8 플래그 |
|
14 ~ 15 |
파티션 1 타입 |
46 ~ 47 |
부트 정보 |
|
16 ~ 17 |
파티션 1 플래그 |
58 ~ 59 |
예약 영역 |
|
18 ~ 19 |
파티션 2 타입 |
60 ~ 63 |
시그니처(0x600DDEEE) |
|
20 ~ 21 |
파티션 2 플래그 |
64 ~ 101 |
예약 영역 |
|
22 ~ 23 |
파티션 3 타입 |
102 ~ 105 |
파티션 1 타임스탬프 |
|
24 ~ 25 |
파티션 3 플래그 |
106 ~ 109 |
파티션 2 타임스탬프 |
|
26 ~ 27 |
파티션 4 타입 |
110 ~ 113 |
파티션 3 타임스탬프 |
|
28 ~ 29 |
파티션 4 플래그 |
114 ~ 117 |
파티션 4 타임스탬프 |
|
30 ~ 31 |
파티션 5 타입 |
118 ~ 121 |
파티션 5 타임스탬프 |
|
32 ~ 33 |
파티션 5 플래그 |
122 ~ 125 |
파티션 6 타임스탬프 |
|
34 ~ 35 |
파티션 6 타입 |
126 ~ 129 |
파티션 7 타임스탬프 |
|
36 ~ 37 |
파티션 6 플래그 |
130 ~ 133 |
파티션 8 타임스탬프 |
|
38 ~ 39 |
파티션 7 타입 |
뭔가 많아 보이지만, 결국 담고 있는 정보는 파티션 개수와 파티션 타입, 플래그, 부트 정보, 시그니처, 파티션 타임스탬프이다.
파티션 타입에는 다음과 같은 값들이 저장된다.
|
값 |
설명 |
값 |
설명 |
|
0 |
비할당 |
6 |
/stand 파티션 |
|
1 |
/boot 파티션 |
7 |
/var 파티션 |
|
2 |
/파티션 |
8 |
/home 파티션 |
|
3 |
Swap |
9 |
대체 섹터 파티션 |
|
4 |
/usr |
10 |
Cahcefs 파티션 |
|
5 |
전체 디스크 |
또 파티션 플래그 값에는 두 가지 값이 있는데 값과 설명은 다음과 같다.
-
1 : 파티션이 마운트 되지 않음을 뜻함
-
128 : 읽기 전용 파티션을 뜻함
이번에는 디스크 맵 구조체 구조이다.
|
범위((Byte) |
설명 |
|
0 ~ 3 |
시작 실린더 |
|
4 ~ 7 |
크기 |
위와 같이 디스크 맵 구조체는 간단한 구조이다.
하지만 위 구조로 봐서는 시작 위치를 정확히 알 수 없기 때문에 섹터로 변환하는 작업이 필요하다.
실린더 주소는 디스크 내 각 플래터 주소 트랙들의 집합이다.
실린더를 섹터로 변환하는 계산식은 다음과 같다.
트랙 당 섹터 수 x 헤드 수 x 실린더 = 실린더 당 섹터 수
트랙당 섹터 수(438 ~ 439)와 헤드 개수(434 ~ 437)는 VTOC 구조체와 디스크 맵을 포함하고 있는 디스크 레이블에서 확인할 수 있다.
i386 시스템
-
해당 시스템을 디스크으 셀치할 때는 하나 이상 도스 파티션이 생성되어야 함
-
일반적으로 도스 파티션 타입 부트 파티션 1개와, 파일 시스템을 사용하는 도스 파티션 타입의 파티션이 생성되어야 함
-
부트 파티션은 당연히 시스템 시작에 필요한 부트 코드를 포함하고 있어야 함
해당 시스템 디스크 레이블은 도스 파티션 타입 파일 시스템 2번째 섹터에 위치하며, 디스크 레이블이 위치한 파티션의 i386 파티션들을 설명한다.
i386 파티션은 반드시 도스 파티션 시작 이후에 시작해야 하며, i386 시스템은 리틀 엔디안 방식을 사용한다.
i386 시스템의 디스크 레이블은 512바이트 크기이며, 모든 파티션 정보가 Sparc 시스템과 달리 디스크 레이블 한 곳에 모여있고 CHS 주소를 사용하여 정보를 저장한다.
다음은 i386 시스템의 디스크 레이블 구조체의 구조이다.
|
범위(Byte) |
설명 |
범위(Byte) |
설명 |
|
0 ~ 11 |
부트 정보 |
156 ~ 167 |
파티션 8 |
|
12 ~ 15 |
시그니처(0x600DDEEE) |
168 ~ 179 |
파티션 9 |
|
16 ~ 19 |
버전 |
180 ~ 191 |
파티션 10 |
|
20 ~ 27 |
볼륨 이름 |
192 ~ 203 |
파티션 11 |
|
28 ~ 29 |
섹터 크기 |
204 ~ 215 |
파티션 12 |
|
30 ~ 31 |
파티션 개수 |
216 ~ 227 |
파티션 13 |
|
32 ~ 71 |
예약 영역 |
228 ~ 239 |
파티션 14 |
|
72 ~ 83 |
파티션 1 |
240 ~ 251 |
파티션 15 |
|
84 ~ 95 |
파티션 2 |
252 ~ 263 |
파티션 16 |
|
96 ~ 107 |
파티션 3 |
264 ~ 327 |
타임스탬프 (사용 x) |
|
108 ~ 119 |
파티션 4 |
328 ~ 455 |
볼륨 레이블 |
|
120 ~ 131 |
파티션 5 |
456 ~ 507 |
하드웨어 세부사항 |
|
132 ~ 143 |
파티션 6 |
508 ~ 509 |
시그니처(0xDABE) |
|
144 ~ 155 |
파티션 7 |
510 ~ 511 |
체크섬 |
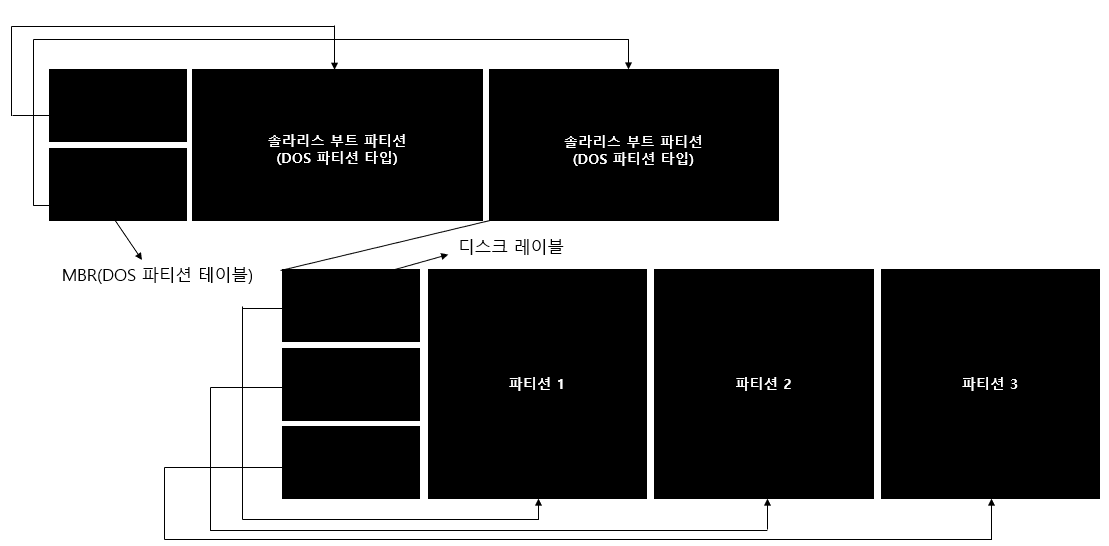
위 표를 보면 디스크 레이블에는 16개의 파티션 엔트리가 있는데 이 파티션 엔트리들의 구조는 다음 표와 같다.
|
범위(Byte) |
설명 |
|
0 ~ 1 |
파티션 타입 |
|
2 ~ 3 |
플래그 |
|
4 ~ 7 |
시작 섹터 |
|
8 ~ 11 |
섹터 크기 |
i386 시스템에서의 파티션 타입과 플래그의 값들은 Sparc 시스템과 동일하다.
i386 시스템의 파티션을 확인하기 위해서는 디스크 레이블의 VTOC 부분을 참고해야 하며 해당 파티션 레이아웃은 파티션 엔트리를 참고하면 된다.
GPT 파티션
-
대부분 고성능 서버에서 쓰임
-
IA64 시스템들은 IA32 시스템처럼 BIOS가 있지 않아 EFI(Extensible Firmware Interface) 시스템을 사용
GPT 파티션을 사용하는 디스크 기본 구조는 다음과 같다.

1)보호용 MBR
-
하나의 엔트리 만을 가진 파티션 테이블을 포함한 도스 파티션이 위치해 있으며 해당 엔트리는 EFI GPT 디스크를 위한 것
-
해당 파티션은 과거 컴퓨터 디스크를 재구성하기 위해 존재
2) GPT 헤더
-
위 그림처럼 두 번째 섹터에 위치
-
GPT 디스크가 생성될 때 고정된 파티션 테이블 위치와 크기를 정의하는 항목 등이 포함
3) 파티션 테이블
-
여러 개의 엔트리가 있으며 해당 엔트리들은 파티션 영역의 파티션들의 타입 등을 정의하는 항목들을 포함
-
윈도우의 경우 GPT 헤더 다음 위치하는 파티션 테이블에 포함되는 엔트리 갯수를 128개로 제한함
4) 파티션 영역
-
GPT 디스크 중에서 가장 큰 공간이며, 파티션 할당에 필요한 섹터들을 포함
-
파티션과 파티션 영역을 혼동하여서는 안 됨
-
이 영역은 GPT 헤더에 의해 정의
5) 백업 영역
-
해당 영역은 파티션에 문제가 발생하였을 경우를 대비하여 GPT 헤더와 파티션 테이블을 복사한 복사본이 존재
GPT 헤더의 오프셋 구조는 다음과 같다.
|
범위(Byte) |
설명 |
범위(Byte) |
설명 |
|
0 ~ 7 |
시그니처(EFI PART) |
48 ~ 55 |
파티션 영역 마지막 LBA |
|
8 ~ 11 |
버전 |
56 ~ 71 |
디스크 GUID |
|
12 ~ 15 |
GPT 헤더 크기(Byte) |
72 ~ 79 |
파티션 테이블 시작 LBA |
|
16 ~ 19 |
GPT 헤더 체크섬(CRC32) |
80 ~ 83 |
파티션 테이블 엔트리 개수 |
|
20 ~ 23 |
예약 영역 |
84 ~ 87 |
파티션 테이블 각 엔트리 크기 |
|
24 ~ 31 |
현재 GPT 헤더의 LBA |
88 ~ 91 |
파티션 테이블 체크섬(CRC32) |
|
32 ~ 39 |
다른 GPT 헤더의 LBA |
92 ~ 섹터 끝 |
예약 영역 |
|
40 ~ 47 |
파티션 영역 시작 LBA |
GPT 파티션은 위 표의 오프셋 구조들을 이용하여 디스크 전체 레이아웃을 정의한다.
다음 표는 GPT 헤더에서 정의한 파티션 테이블의 각 엔트리들이 오프셋 구조이다.
|
범위(Byte) |
설명 |
범위(Byte) |
설명 |
|
0 ~ 15 |
파티샨 타입 GUID |
40 ~ 47 |
파티션 LBA 마지막 |
|
16 ~ 31 |
고유 파티션 GUID |
48 ~ 55 |
파티션 속성 |
|
32 ~ 39 |
파티션 LBA 시작 |
56 ~ 127 |
파티션 이름 (유니코드) |
GUID는 128bit로 파티션 내용을 구분하는 데 사용된다.
인텔과 MS에서 정의한 GUID 값이 있는데 그 값들은 다음 표와 같다.
|
GUID |
설명 |
|
00000000-0000-0000-000000000000 |
비할당된 엔트리 |
|
C12A7328-F81F-11D2-BA4B-00A0C93EC93B |
EFI 시스템 파티션 |
|
024DEE41-33E7-11D3-9D69-0008C781F39F |
도스 파티션 테이블 내부에 있는 파티션 |
|
GUID |
설명 |
|
E3C9E316-0B5C-817D-F92DF00215AE |
마이크로소프트 예약 파티션(MRP) |
|
EBD0A0A2-B9E5-4433-87C0-68B6B72699C7 |
주 파티션(기본 디스크) |
|
5808C8AA-7E8F-42E0-85D2-E1E90434CFB3 |
LDM 메타데이터 파티션(동적 디스크) |
|
AF9B60A0-1431-4F62-BC68-3311714A69AD |
LDM 데이터 파티션(동적 디스크) |
위 표가 인텔에서 정의한 GUID이고, 아래 표가 MS에서 정의한 GUID이다.
MS에서 정의한 파티션 중 예약 파티션은 임시 파일을 보관하기 위한 파티션이고 주 파티션은 우리가 알고 있는 하나의 파일 시스템을 사용하는 파티션이다.
해당 파티션을 지원한느 분석 도구는 아직까지 많지 않다.
하만 앞으로 64bit 시스템이 주를 이루어 사용하는 날이 얼마 남지 않아 해당 시스템에 대한 분석 도구의 지원이 절실할 때이다.
해당 시스템을 가지는 디스크를 분석할 때에는 다른 파티션들과 같이 비할당 영역의 데이터를 찾아 반드시 분석해야 한다.
# Reference
'Digital Forensics > Forensic Theory' 카테고리의 다른 글
| [Digital Forensic] FAT 파일 시스템 (1) (0) | 2020.03.28 |
|---|---|
| [Digital Forensic] RAID & Disk Spanning (0) | 2020.03.28 |
| [Digital Forensic] 하드 디스크와 데이터 수집 (0) | 2020.03.27 |
| [Digital Forensic] 메모리 분석 (2) (0) | 2020.03.27 |
| [Digital Forensic] 메모리 분석 (1) (0) | 2020.03.27 |