[DataBase] 데이터베이스 구조

(1) 데이터베이스 구조
-
데이터베이스를 물리적 공간을 이해하기 쉽게 논리적으로 구체화
-
Table Space, Segment, Extent, Block 단위로 나뉨

테이블 스페이스(Table Space) 안에는 데이터 파일이 존재하며, 데이터 파일은 세그먼트(Segment)로 구성된다.
각각의 세그먼트는 익스텐트(Extent)로 구성되고, 익스텐트는 블록(Block)으로 구성된다.
상위 개념과 크기 순서로 나열하면 다음과 같다.
-
1. 테이블 스페이스 (Table Space)
-
2. 데이터 파일 (Data File)
-
3. 세그먼트 (Segment)
-
4. 익스텐트 (Extent)
-
5. 블록 (Block)
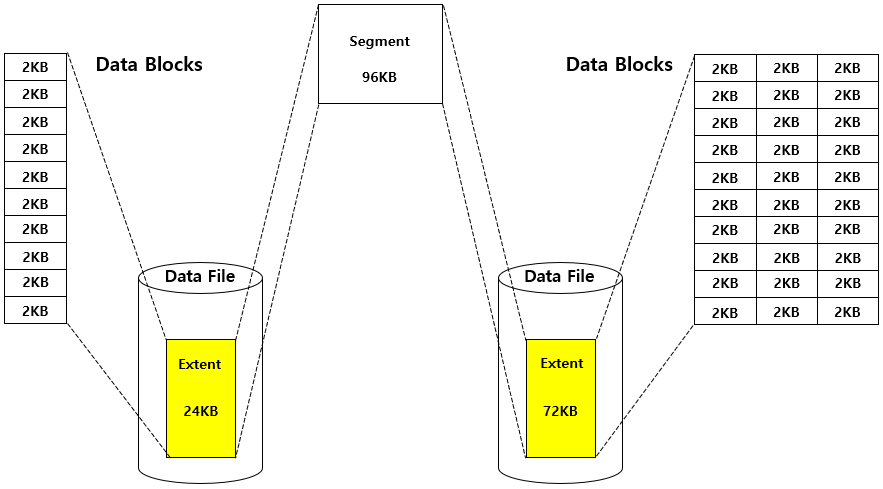
1-1. Data Block (Block 또는 Page)
-
데이터베이스에서 데이터를 저장하는 가장 작은 단위 데이터 블록
-
물리적 디스크 공간 크기에 따라 데이터 블록 크기도 결정됨
-
위 그림을 예로 들자면, 데이터 블록의 크기는 2KB
-
데이터 블록은 담고 있는 데이터를 추적하고 비어있는 공간을 수월하게 찾기 위해 일정한 형식을 가짐
사용자가 입력한 데이터는 테이블에 저장되고 테이블은 물리적 파일 안에 데이터 블록 단위로 분할되어 저장된다.
데이터 블록은 헤더와 Row 디렉토리로 구성되며, 헤더는 각 블록에 대한 기본 정보를 담고 있고, Row 디렉토리는 각각의 Row를 가리키는 오프셋 목록을 가지고 있다.
Row 디렉토리 안에는 Flag(플래그) 값도 포함되어 있는데, 플래그 값은 해당 Row의 삭제 여부를 알려준다.
데이터 블록의 구조는 다음 그림과 같다.

가) Block Header
-
물리 디스크 주소나 데이터 블록에 대한 일반적인 정보를 담음
-
블록을 업데이트한 모든 트랜잭션에 대해서는 트랜잭션 엔트리가 필요하며, 그것에 대한 정보 또한 Block Header가 담음
-
대부분 운영체제에서 트랜잭션 엔트리는 약 23Byte 정도가 필요
나) Table Directory
-
데이터 블록 안에 레코드 데이터가 저장된 테이블에 대한 메타데이터를 담고 있는 영역
-
하나의 데이터 블록은 여러 테이블의 레코드를 저장하고 있을 수 있음
다) Row Directory
-
데이터 블록 특정 위치에 저장된 레코드 데이터 위치 정보를 담고 있는 영역
-
해당 영역은 한 번 레코드 삭제 이후에도 재할당 받을 수 없음
-
새로운 레코드가 데이터 블록에 추가되었을 때만 해당 공간을 다시 사용 가능
-
각각의 Row는 Row Directory에 있는 슬롯을 가짐
-
슬롯은 Row 데이터의 시작을 가리킴
Block Header, Table Directory, Row Directory를 총칭하여 블록 오버헤드(Block Overhead)라고 한다.
일부는 고정된 크기를 갖지만, 총 사이즈는 가변적이다.
대부분 블록 오버헤드의 총 사이즈는 84에서 107Byte 정도이다.
라) Row Data
-
테이블 레코드나 인덱스 키 엔트리 등과 같은 실제 데이터를 담고 있는 곳
-
모든 데이터 블록이 내부 구조로 되어 있듯이 모든 레코드들도 데이터베이스가 원하는 데이터를 수월하게 찾기 위한 형식 존재
-
하나의 Row는 여러 개의 Row 조각들로 구성
-
각각의 Row 조각은 Row 헤더와 Column 데이터로 구성
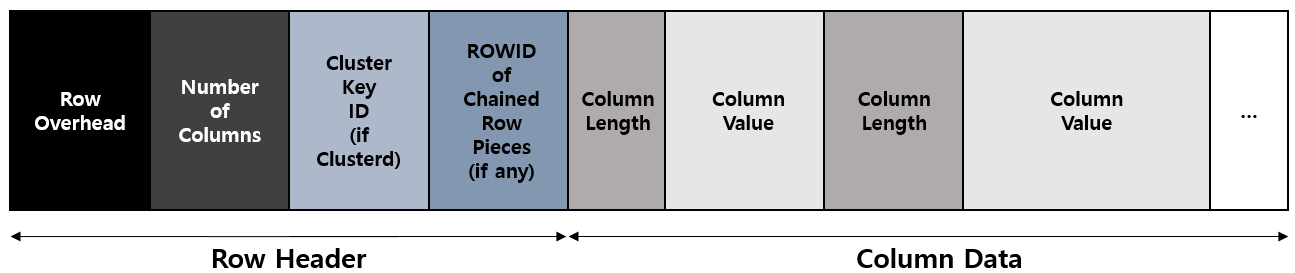
마) Row Header
-
데이터베이스에 저장된 Row Piece들을 관리하는 데 필요한 영역
-
Row Piece에 있는 Column들과 데이터 블록 안에 저장된 다른 Row Piece에 대한 정보, 클러스터 키 정보를 가지고 있음
-
블록 하나를 온전히 차지하는 Row는 최소 3Byte의 Row 헤더를 가짐
일반적으로 Row는 하나의 데이터 블록에 담아지는 크기라 보통 하나의 Row Piece로 저장하지만, 하나의 데이터 블록에 담기에는 Row의 크기가 너무 크거나 업데이트로 인해 기존 Row 크기가 블록 크기를 넘어갈 경우, 여러 개의 Row Piece에 데이터를 저장한다.
RowID는 데이터베이스가 각 Row를 고유하게 식별하기 위한 것이다.
데이터베이스가 Row에 접근하기 위한 정보를 담고 있으며, 각 Row의 물리 주소를 Base64로 인코딩한 형식을 사용하며 확장형 RowID는 데이터 오브젝트 넘버를 포함한다.

ROWID 값으로 AAAR59AABAAALohAAA가 나왔다고 가정하자.
ROWID는 4부분으로 나뉘며, 다음 그림과 같이 나눌 수 있다.

[표 1] ROWID 구분과 설명
| 값 | ROWID 구분 | 설명 |
| AAAR59 | Data Object Number | 해당 Row를 담고 있는 세그먼트 식별 |
| AAB | Relative File Number | 해당 Row를 담고 있는 데이터 파일 식별 |
| AAALoh | Block Number | 해당 Row를 담고 있는 블록 식별 |
| AAA | Row Number | Row 식별 |
바) Column Data
-
Row의 실제 데이터를 담는 공간
-
Column 데이터는 CREATE TABLE로 명시한 Column 이름 순서대로 넣어짐
1-2. Extent
-
데이터 블록이 연속적으로 할당된 것
-
24KB의 익스텐트는 12개의 2KB 데이터 블록을 연속적으로 할당 받은 것이 됨
-
72KB의 익스텐트라면 데이터 블록 36개가 연속적으로 할당된 것
-
특정 타입의 정보를 저장하기 위한 단위
1-3. Segment
-
데이터베이스 테이블의 특정 오브젝트를 담기 위해 할당되는 단위 (한 개 이상의 익스텐트 모음)
-
해당 테이블 안의 데이터는 데이터 세그먼트에 저장
-
테이블의 인덱스 정보는 인덱스 세그먼트에 저장
-
모든 데이터베이스 오브젝트는 각각의 세그먼트에 저장
1-4. Table Space
-
실제 데이터를 물리적으로 저장하는 공간
-
데이터베이스의 레코드와 테이블 스키마 정보가 이곳에 들어 있음
# Reference
'DB' 카테고리의 다른 글
| [DataBase] 데이터베이스 포렌식 개요 (0) | 2020.05.01 |
|---|---|
| [DataBase] 데이터베이스 포렌식 도구 (0) | 2020.03.20 |
| [DataBase]DCL (데이터 제어어) (0) | 2020.03.20 |
| [DataBase] DML (데이터 조작어) (0) | 2020.03.20 |
| [DataBase] DDL (데이터 정의어) (0) | 2020.03.20 |