[DataBase] DML (데이터 조작어)

(1) DML (Data Mgnipulation Language, 데이터 조작어)
-
데이터베이스의 데이터 조회나 검색하는 명령어 SELECT
-
데이터 삽입, 수정, 삭제하는 명령어 INSERT, UPDATE, DELETE
가) SELECT
-
데이터베이스에서 원하는 데이터 조회
-
다양한 활용 가능
-
매우 자주 쓰이는 명령어 중 하나

SELECT는 원하는 데이터를 뽑아내고 자 할 때 가장 많이 쓰는 쿼리 명령어로 WHERE, LIKE, HAVING, JOIN 등의 구문과 함께 쓰일 수 있다.
SELECT를 다음과 같이 다양하게 활용 가능하다.
AS
-
SELECT로 선택한 Column에 별칭을 부여하는 역할
-
결과 테이블이 출력될 때 Column 이름은 별칭으로 나타남

ORDER BY
-
결과 테이블의 레코드를 오름차순 또는 내림차순으로 정렬

WHERE
-
SELECT 구문에 조건을 추가할 때 사용
-
일반적 구문 형식은 가장 기본적인 select ~ from 구문 뒤에 where 키워드와 조건을 붙임

조건식은 주로 'Column 이름', '연산 기호', '조건 값' 순서로 온다.

LIKE
-
WHERE 구문 안에 위치
-
SELECT에서 뽑은 Column 안의 문자열 데이터의 패턴을 명시하여 찾을 때 사용
-
조건절에서 어떻게 사용하느냐에 따라 수많은 로그에서 내가 원하는 로그만을 출력할 때 매우 유용하게 사용

문자열의 패턴을 명시할 때는 와일드카드라는 것을 사용한다.
DB 종류마다 와일드카드가 조금씩 다르며, 다음 표와 같이 대표적인 와일드카드가 있다.
[표 1] 와일드카드 설명
| 기호 | 설명 | 예시 |
| % | 0개 또는 여러 개의 문자가 올 수 있다는 의미 | se%는 se, seek, seel, sell, secret 등 se로 시작하는 문자열 의미 c%t는 cat, cut 등 c로 시작하고 t로 끝나는 문자열 의미 %p는 app, cup, sip 등 p로 끝나는 문자열 중 하나를 의미하며, 0개의 문자열이 올 수도 있으므로 p도 해당 |
| _ | 하나의 문자가 올 수 있다는 의미 | s_t는 sit, sat 등 s와 t 사이에 하나의 문자가 오는 문자열 의미 |
| [] | []안에 명시한 문자들 중 하나의 문자가 올 수 있다는 의미 | h[i,a]t는 hit 또는 hat을 의미 |
| - | 문자의 범위를 나타낼 때 사용 | h[a-l]t는 h와 t 사이에 a부터 l 중 하나의 문자가 올 수 있다는 것을 의미 hat, hit가 여기에 해당 |
| ^ | NOT을 의미 | h[^a-l]t는 h와 t 사이에 a부터 l까지의 문자를 제외한 다른 하나의 문자만이 들어올 수 있다는 것을 의미 hat, hit은 여기에 포함되지 않고, hot, hut이 포함 |
MS Access의 경우 %는 *로, _는 ?로, ^는 !로 사용하며, 하나의 숫자 문자를 나타낼 때는 #을 사용한다.
AND, OR, NOT
-
WHERE 구문과 함꼐 조건문을 만족하는 레코드만을 뽑아낼 때 사용

BETWEEN
-
WHERE 구문에서 조건을 명시할 때 값의 범위 표현

IN
-
WHERE 구문의 조건에서 다양한 값을 명시할 때 사용

IN 안에 또 다른 SELECT 구문을 사용하여 조건에 여러 값을 명시할 수 있다.

IN 안의 SELECT 구문이 가장 먼저 수행 된다.
먼저 email_list 테이블에서 email 문자열 데이터가 '@gmail.com'으로 끝나는 것들 중 user_name을 뽑아낸다.
여기서 뽑아낸 데이터들이 바깥에 있는 WHERE 구문 emp_name의 조건 값이 된다.
만약 IN 안의 SELECT 구문을 실행하여 얻어낸 데이터들이 'Betty', Carol', 'Demian' 이라면 employee_table에서 emp_name이 'Betty', 'Carol', 'Demian'인 레코드의 emp_name과 emp_num 정보를 보여주는 결과 테이블이 출력된다.
COUNT, SUM, AVG, MIN, MAX
-
다음과 같은 함수를 집계 함수라고 하며, 숫자 데이터를 계산할 때 유용
-
COUNT는 조건을 만족하는 모든 레코드의 개수를 셈
-
SUM은 숫자 값을 담는 Column의 데이터 총 합을 계산
-
AVG는 숫자 값을 담는 Column의 데이터 평균 값을 계산
-
MAX는 해당 Column의 가장 큰 값을 반환
-
MIN은 해당 Column의 가장 작은 값을 반환

HAVING ~ GROUP BY

GROUP BY는 주로 위에서 소개한 집계 함수와 함께 쓰인다.
집계 함수의 결과를 특정 Column을 기준으로 그룹을 짓는 역할을 한다.
HAVING은 GROUP BY와 함께 쓰이며 집계 함수 조건절을 추가할 때 사용한다.
[표 2] Group By 실행 결과 테이블
| Employee Number | Country |
| 20 | USA |
| 15 | China |
| 11 | Argentina |
| 8 | Germany |
| 5 | France |
| 4 | Canada |
| 4 | UK |
| 3 | Brazil |
| 2 | Korea |
JOIN
-
둘 이상의 테이블이 서로 연관된 Column을 가지고 있을 때 JOIN 명령으로 테이블들의 레코드 결합 가능
테이블 1 : Order_Info
| cust_num | cust_name | order_date | total_charge |
| 001 | Alice Green | 2020-01-04 | 257,800 |
| 002 | Bob Smith | 2020-01-01 | 25,000 |
| 003 | Carol White | 2020-01-02 | 65,000 |
| 004 | Daniel Cruze | 2020-01-03 | 147,350 |
테이블 2 : Customer_Info
| cust_num | user_ID | birth | |
| 001 | alice0306 | hialice_0306@gmail.com | 1997-03-06 |
| 003 | sing_carol | sing_carol@gmail.com | 1998-10-15 |
| 005 | espressoholic | needscaffein@gmail.com | 1995-11-17 |
| 008 | blacksheep_DC | blacksheep_DC@gmail.com | 1999-06-23 |
위 두 개 테이블에서 동일한 Column은 cust_num이다
따라서 cust_num을 기준으로 두 개의 테이블을 결합할 수 있다.
JOIN은 결합 형식에 따라 INNER JOIN, LEFT JOIN, RIGHT JOIN이 있다.
INNER JOIN
-
두 테이블에 모두 매치되는 값을 가진 레코드만 반환

| cust_name | user_ID | |
| Alice Green | alice0306 | hialice_0306@gmail.com |
| Carol White | sing_carol | sing_carol@gmail.com |
LEFT (OUTER) JOIN
-
반드시 출력되는 테이블을 결정

| cust_name | user_ID | |
| Alice Green | alice0306 | hialice_0306@gmail.com |
| Carol White | sing_carol | sing_carol@gmail.com |
| NULL | espressoholic | needscaffein@gmail.com |
| NULL | blacksheep_DC | blacksheep_DC@gmail.com |
왼쪽 테이블은 반드시 출력되어야 하므로, Customer_Info의 cust_num과 일치하지 않는 레코드로 출력
(위 예문에서는 Order_Info)
RIGHT (OUTER) JOIN
-
반대로 오른쪽 테이블이 반드시 출력

| cust_name | user_ID | |
| Alice Green | alice0306 | hialice_0306@gmail.com |
| Bob Smith | NULL | NULL |
| Carol White | sing_carol | sing_carol@gmail.com |
| Daniel Cruze | NULL | NULL |
이번에는 오른쪽 테이블(Customer_Info)이 반드시 출력된다.
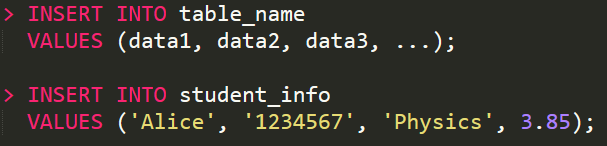
나) INSERT INFO
-
테이블에 새로운 레코드를 추가
-
테이블의 Column이 어떠한 순서로 조직되어 있는지 모른다면, 테이블명 뒤에 Column을 나열
-
그 순서대로 VALUES 뒤에 추가할 데이터를 입력

만약 테이블의 Column 순서를 알고 있다면, 위 예시처럼 Column을 나열할 필요가 없다.
다만 추가할 데이터를 반드시 Column 순서대로 입력해야 한다.
다) UPDATE
-
테이블의 레코드 데이터를 갱신

WHERE 절로 데이터를 갱신할 레코드를 지정해주지 않으면 테이블의 모든 레코드 데이터가 갱신되므로 주의한다.

라) DELETE
-
테이블의 레코드 데이터 삭제
-
UPDATE와 마찬가지로 WHERE 절로 갱신할 레코드를 지정해주지 않으면 테이블의 모든 레코드 데이터 삭제

# Reference
'DB' 카테고리의 다른 글
| [DataBase] 데이터베이스 포렌식 도구 (0) | 2020.03.20 |
|---|---|
| [DataBase]DCL (데이터 제어어) (0) | 2020.03.20 |
| [DataBase] DDL (데이터 정의어) (0) | 2020.03.20 |
| [DataBase] DBMS(Database Management System) (0) | 2020.03.18 |
| [DataBase] 데이터베이스 모델 (0) | 2020.03.16 |